A living room has a coffee table with a basket on it, a wooden floor, a TV on a TV stand, and a sofa with an astronaut sitting on it
A table with a roasted turkey, a salad, a loaf of French bread, a glass of orange juice and an empty plate
Panda in a wizard hat sitting on a Victorian-style wooden chair and looking at a Ficus in a pot
GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guidedGenerative Gaussian Splatting
Abstract
In this paper, we propose a generative 3D Gaussians with Layout-guided control, GALA3D, for effective compositional text-to-3D generation in a user-friendly way. To this end, we utilize large language models (LLMs) for generating initial layout descriptions and introduce a layout-guided 3D Gaussian representation for 3D content generation with adaptive geometric constraints. We then propose an object-scene compositional optimization mechanism with conditioned diffusion to collaboratively generate realistic 3D scenes with consistent geometry, texture, scale, and accurate interactions among multiple objects while simultaneously adjusting the coarse layout priors extracted from the LLMs to align with the generated scene. Experiments show that GALA3D presents a user-friendly, end-to-end framework for state-of-the-art scene-level 3D content generation and controllable editing while ensuring the high fidelity of object-level entities within the scene. Source codes and models will be available.

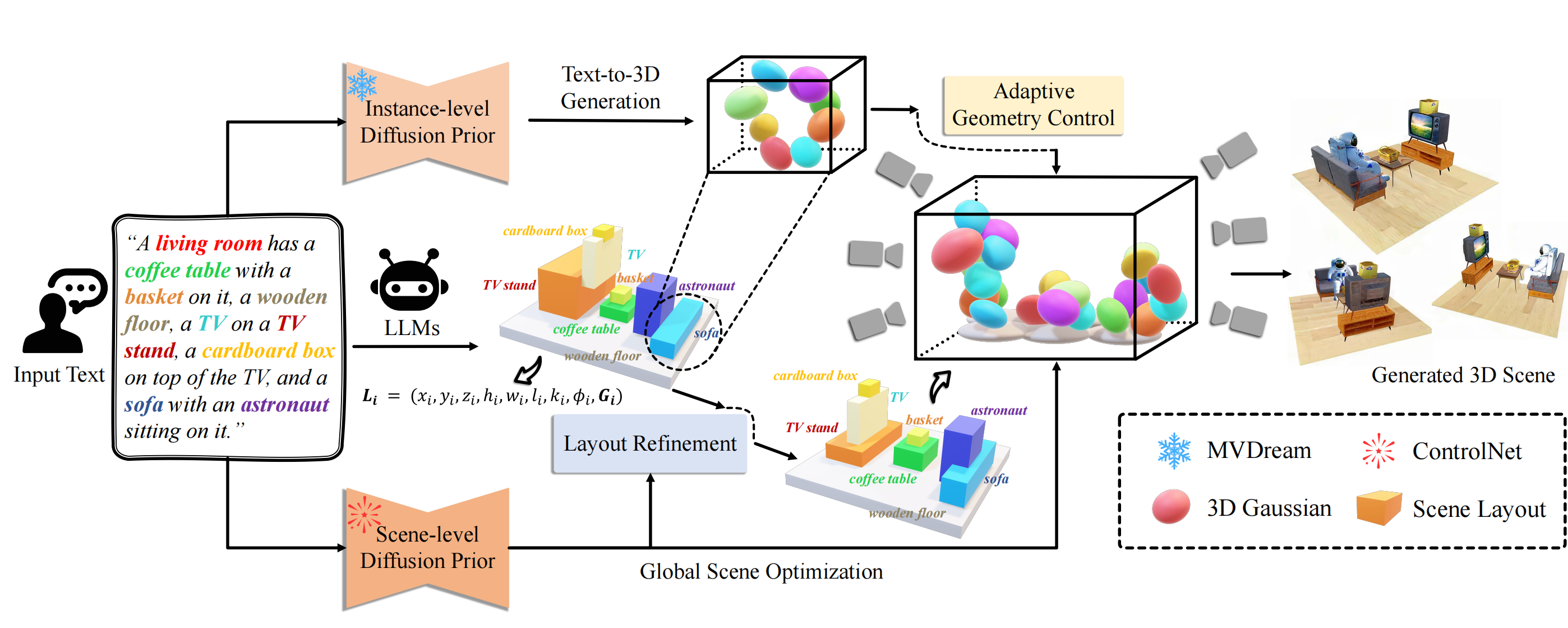
Framework
Overall framework of GALA3D. Given a textual description, GALA3D first creates a coarse layout using LLMs. The layout is then utilized to construct the Layout-guided Gaussian Representation, incorporating Adaptive Geometry Control to constrain the Gaussians' geometric shape and spatial distribution. Subsequently, Compositional Diffusions are employed to optimize the 3D Gaussians using text-to-image priors compositionally. Simultaneously, the Layout Refinement module refines the initial layout provided by LLMs, enabling a better adherence to real-world scene constraints.
Comparison Results
Qualitative comparisons between our method and SJC, ProlificDreamer, MVDream, DreamGaussian, GaussianDreamer, GSGEN, and Set-the-Scene.

More Generated Samples
More generated samples by our GALA3D.
A bedroom with a Baroque bed, two wooden nightstands, a square wooden table with a potting on it, and a wooden wardrobe
A cat lies on a plank of wood suspended from two balloons
Chess is on the table next to two stones
A Victorian style wooden chair on an oak floor with a Ficus in a pot next to it
A puppy lying on the iron plate on the top of Great Pyramid
A table with a hamburger, a bread, an order of fries, and a cup of Coke
A table with a roasted turkey, a salad, a loaf of French bread, a glass of orange juice and an empty plate
A camping scene with a tent on the grassland and two benches next to a campfire
A kitchen with a kitchen stove, a range hood, a refrigerator, a tile floor, and a microwave on the table
A living room has a coffee table with a basket on it, a wooden floor, a TV on a TV stand, and a sofa with an astronaut sitting on it
A table with models of teddy bears, marlin (clown fish), Hello Kitty, Mickey Mouse, Stitch, Snoopy, Donald Duck, Santa Claus, SpongeBob SquarePants, and Patrick Star in the shape of a heart
An octopus playing the piano
Panda in a wizard hat sitting on a Victorian-style wooden chair and looking at a Ficus in a pot
An amusement park swing, a seesaw, a street lamp on the grass
A rabbit eating birthday cake at the dining table
Scene Editing
Editing scenes using prompt.